Intrinsic functions are Dataset manipulations that can be added to queries. They are accessed from the following locations:
- Dataset Scratch Right-Click
- HotBar Right-Click
- Dataset Builder Right-Click
Available intrinsic functions are:
- invert()
- random(X)
- random%(X.XX)
- sample(X)
- top(X)
- bottom(X)
- firstdiscrete(table.field)
- lastdiscrete(table.field)
- lowdiscrete(table, table.field)
- highdiscrete(table, table.field)
- topby(table.field, X)
- bottomby(table.field, X)
Invert
Inverting a DataSet flips every record in the DataSet. The records that were IN the DataSet will be OUT, and the records that were OUT will be IN. Think of this as flipping every 0 to 1, and every 1 to 0. In the example below, the DataSet comes from a table that has 5 rows. Initially there were 3 records in the selection (count of 3). After inverting the DataSet count is 2:
| Record No | DataSet 1 | DataSet 1 |
|---|---|---|
| 1 | 0 | 1 |
| 2 | 1 | 0 |
| 3 | 1 | 0 |
| 4 | 0 | 1 |
| 5 | 1 | 0 |
| Total | 3 | 2 |
If the DataSet comes from a table of 1 million rows, and the DataSet count is 100,000, inverting it will result in DataSet of 900,000 rows.
Random
Selecting Random brings up the Random Size Dialog. Enter a number X between 0 and N, where N is the DataSet Count:
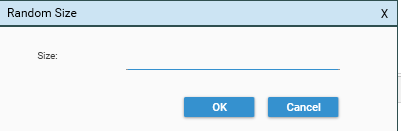
The resulting DataSet will contain X records randomly sampled from the original DataSet.
Random%
Selecting Random% will show the Random Percent Dialog. Enter an integer or decimal number X between 0 and 100:
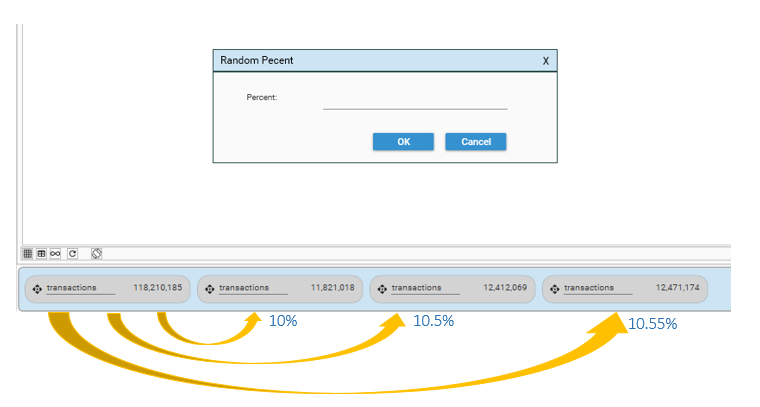
The resulting DataSet will contain X% of randomly sampled records from the original DataSet.
Sample
Selecting Sample will show the Sample Dialog. Enter a number to perform a 1 in N sample, ie., select every Nth record.
Top
Selecting Top will show the Top Size Dialog. Enter an integer number X between 0 and N, where N is the DataSet Count.
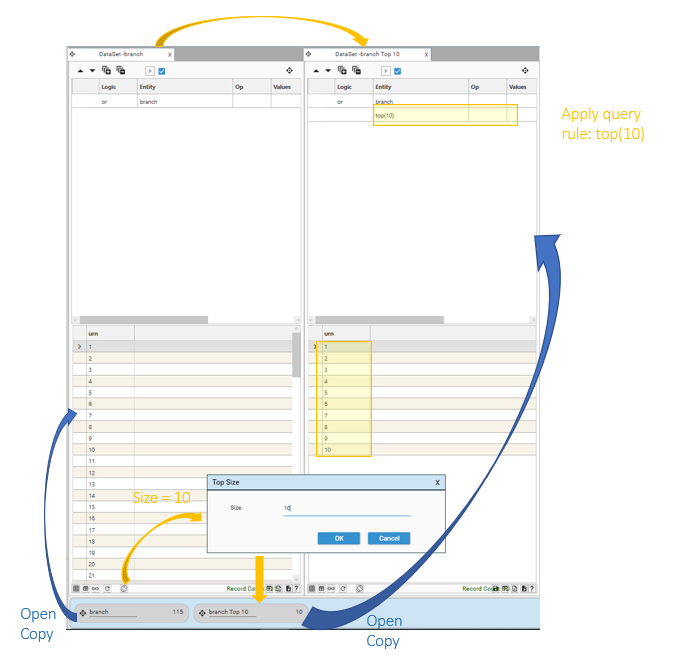
The resulting DataSet will contain the first N records from the original DataSet.
Bottom
Selecting Bottom will show the Bottom Size dialog. This works in the same way as the Top function but selects from the bottom of the dataset.
First Discrete
First Discrete selects the first occurrence of each unique value for a particular field within the original DataSet. In the example below, where there are 5 records in the original DataSet, applying function FirstDiscrete on Product Group gives 3 records (first occurrence of Group1, Group2 and Group3). Applying function FirstDiscrete on Price gives 4 records (first occurrence of 10.99, 15.0, 79.65, 10.98)
| Record No | Product Group | Price | FirstDiscrete (Product Group) | FirstDiscrete (Price) |
|---|---|---|---|---|
| 1 | Group1 | 10.99 | 1 | 1 |
| 2 | Group1 | 15.00 | 0 | 1 |
| 3 | Group3 | 79.65 | 1 | 1 |
| 4 | Group2 | 15.00 | 1 | 0 |
| 5 | Group3 | 10.98 | 0 | 1 |
| Total | 3 | 2 | 3 | 4 |
In the example below, applying First Discrete on Date filters a DataSet of 118,210,185 records to 700 as there are 700 unique dates in the transaction table:
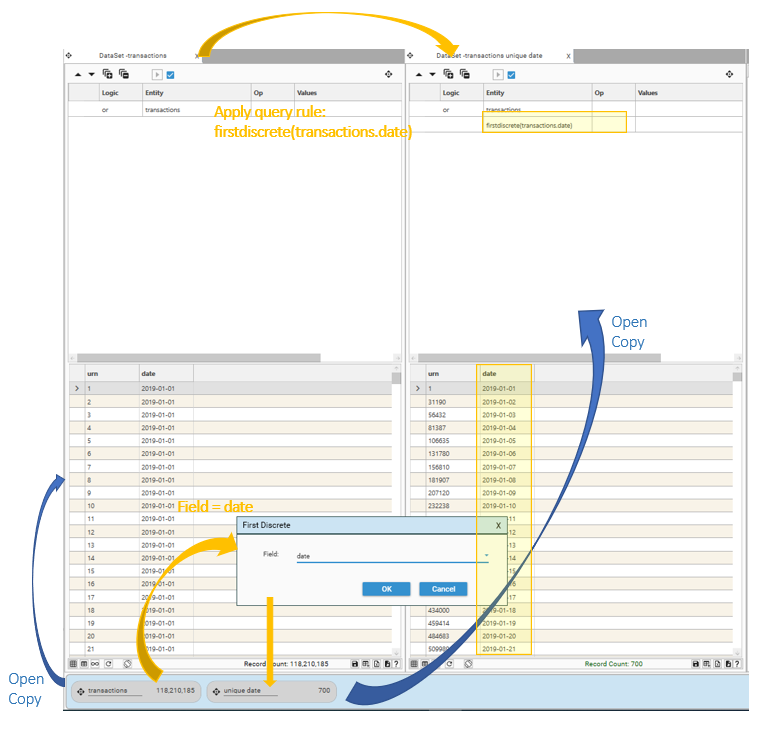
For more detail on First Discrete, see FirstDiscrete.
Last Discrete
Last Discrete uses the same mechanism as First Discrete, but selects for the last occurrence rather than the first occurrence. So Last Discrete selects the last occurrence of each unique value for a particular field within the original DataSet.
First and Last are determined by URN - i.e., the order in which the records appear in the DataSet's owner table.
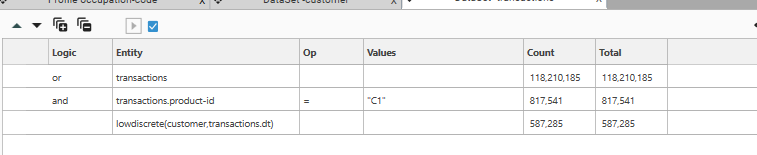
Low Discrete
Low Discrete selects a record based on the lowest value of a "scoring" field. So Low Discrete selects one record for each unique value in a key table. Where more than one occurrence of the key is found, the record that has the lowest value in the scoring field is selected.
So for example, in a table of sales transactions, Low Discrete could be used to select the first transaction where the customer bought a specific product:

High Discrete
High Discrete selects a record based on the highest value of a "scoring" field. So High Discrete selects one record for each unique value in a key table. Where more than one occurrence of the key is found, the record that has the highest value in the scoring field is selected.
So for example, in a table of sales transactions, High Discrete could be used to select the sales transaction with the greatest discount for each customer:
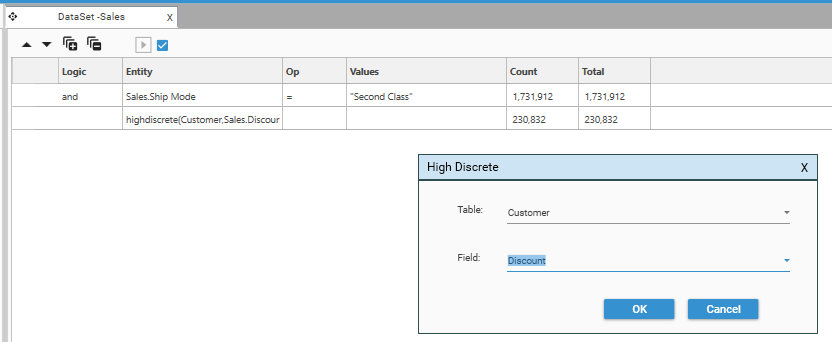
To bring up the High Discrete dialog, right-click in the Dataset Query Rule tree and choose Function | HighDiscrete
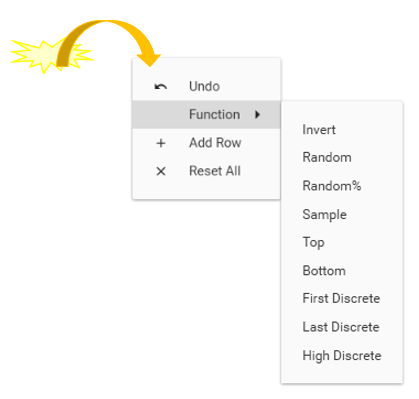
- Table: Must be linked to the query resolution table, and must be the primary table (i.e., on the ONE side of a ONE to MANY link)
- Field: Must be numeric, and on the query resolution table.
It is not possible to edit a High Discrete Query element in the query tree - first delete the existing element and then add another element.
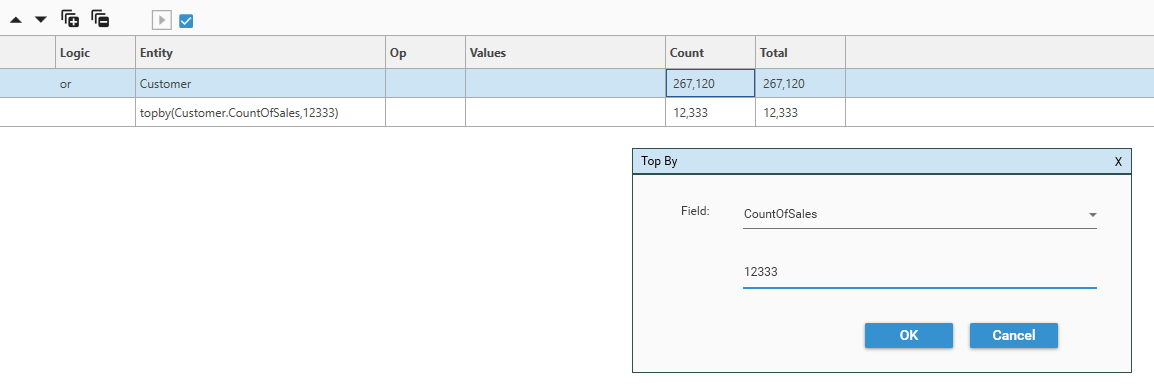
Top By
BETA
Top By sorts the dataset by the specified field (sort direction is ascending) and then selects the first X records in the dataset. Note that the data returned from Top By is in URN order, not the sorted order in which the selection was made.
To bring up the Top By dialog, right-click in the Dataset Query Rule tree and choose Function | Top By
Select a measure to sort by and the number of records that are required:
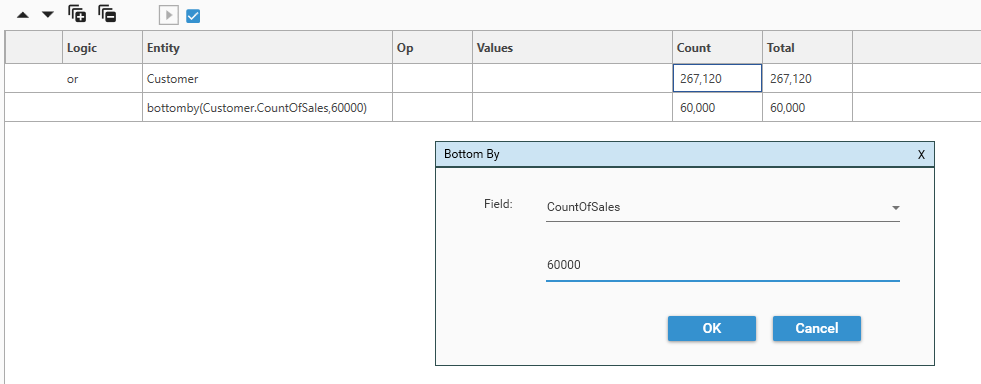
Bottom By
BETA
Bottom By sorts the dataset by the specified field (sort direction is ascending) and then selects the last X records in the dataset. Note that the data returned from Bottom By is in URN order, not the sorted order in which the selection was made.
To bring up the Bottom By dialog, right-click in the Dataset Query Rule tree and choose Function | Bottom By
Select a measure to sort by and the number of records that are required: