Article In Progress - Content May Change...
Overview
The Audience Selection solution loads and processes daily segmentation files, received from a vendor, into a DataSource that is then used to:
- Create and schedule regular audience data extracts as part of the Audience Extract Solution
- Allow datasource segmentation to be accessed by DataHub customers via a DataHub Package

Audience Extract Solution
The Audience Extract Solution supports the creation and extraction of "audiences". An Audience is a set of selection rules, generated from vendor supplied segment data. These segment data are accessed via the campaign selection interface, either in DataJet Desktop, or in the Audiences Web App.
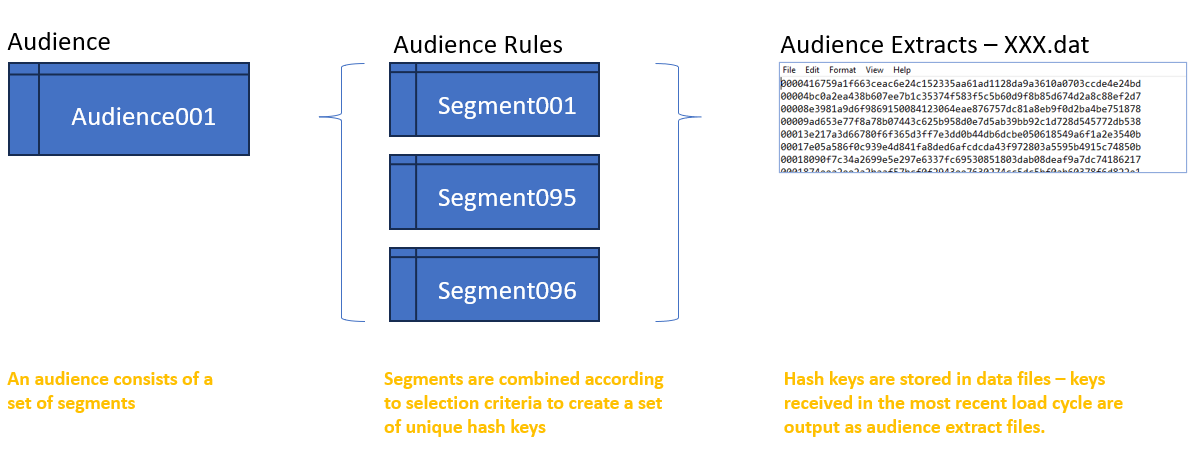
Load Projects & Scripts
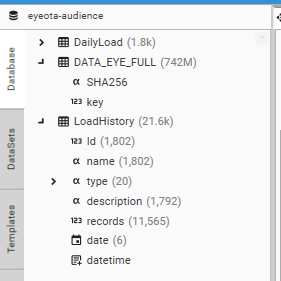
The system requires 2 main load projects, referred to here as dsource1-incremental and dsource1-audience.
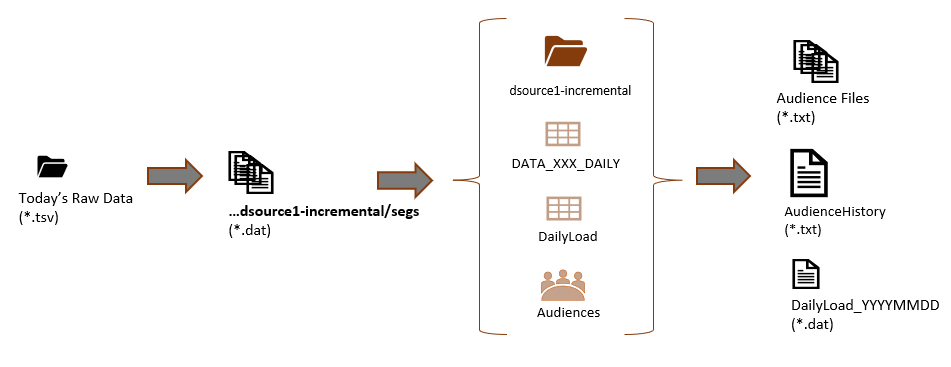
- dsource1-incremental: the project that processes todays data and contains data used to create daily audience extracts.
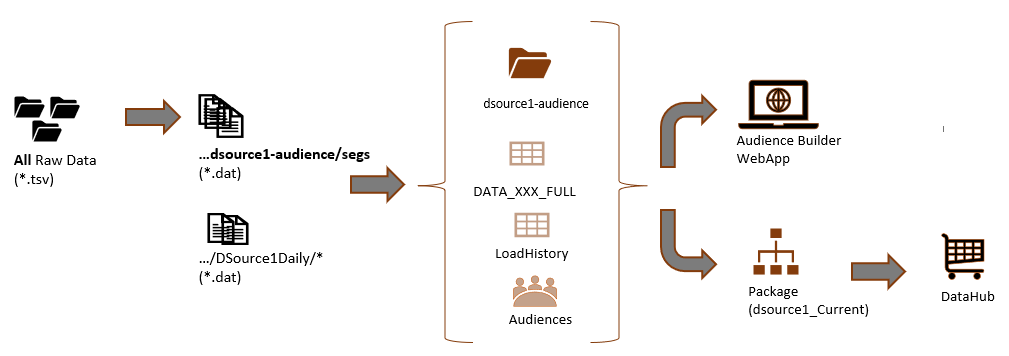
- dsource1-audience: the project that contains the data used to create new audiences. This is the data sitting underneath the Audience Builder Solution and DataHub Package and contains data for a multi-day period.
Project: dsource1-incremental
dsource1-incremental is the project used to create daily audience extracts - it contains only the data received for the active day's processing. The following process is used:
- Active day's raw data files are processed (using ProcessSegements)
- Segment data for those files are stored in the campaign storage system (...dsource1-incremental/segs)
- Unique Hash-keys are loaded into the PRIMARY CONTACT TABLE (DATA_XXX_DAILY) (using CreateTableFromFile) where XXX is the vendor 3 digit code
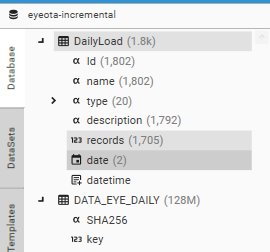
- A daily load history file is created and loaded into table (DailyLoad) (using GetCampaignHistory and targetTable)
- Existing audiences are re-imported into the project (using ImportAudienceDefinitions)
- Audience Definitions are used to create extract files and metadata (via BulkExportAudiences)
- Today's Load History is added to the .../DataSource1Daily history folder (DailyLoad_YYMMDD...dat)
- Audience extract files are sent back to vendor
Project: dsource1-audience
Dsource1-audience is the multi-day project used to create new audiences and the package that is injected as part of the datahub solution. The following process is used:
- Raw data files are processed (usually 7-15 days worth, up to a limit of 1.8 billion "Hash-Keys", where a Hash is an encoded email) (using ProcessSegments)
- Segment data are stored in the campaign storage system (...dsource1-audience/segs)
- Unique Hash-keys are loaded into the PRIMARY CONTACT TABLE (DATA_XXX_FULL)
- A daily load history table (DailyLoad) is created (using GetCampaignHistory and targetTable)
- An Extract history table (LoadHistory) is created by loading all daily load reports generated by project dsource1-incremental (using CreateTableFromFile and folder DSource1Daily)
- The Audience Builder app connects to the project and uses segmentation data to build, edit and schedule audiences for extract.
- A package is built and distributed so that the segmentation data can be used by other projects (e.g., DataHub)
{
...
"alternatePath" : "/home/engine/datasources/campaignRoot/onetouch-dev01/dsource1-audience/segs",
...
}
{
...
"alternatePath" : "/home/engine/datasources/campaignRoot/onetouch-dev01/dsource1-incremental/segs",
...
}
For more detail on campaign definition files, see Campaign Prototype: How to make a system campaign enabled
API Call Overview
The following API calls support these processes and applications
- AudienceDelete - Deletes an audience
- AudienceLS - Provides a list of audiences
- AudiencePush - Adds or updates audience details
- AudienceRename - Renames an existing audience
- BulkExportAudiences - Create audience extract files and summary metadata
- CountCampaignDataset - Returns number of records in an audience
- CreateCampaignDataset - Adds a dataset field to the Primary Contact Table that shows membership of an audience
- ExportAudience - Exports the hash-keys for an audience to file
- GetCampaignHistory - Creates a segmentation and audience overview report, listing segmentations and the number of records
- ImportAudienceDefinitions - Imports a set of audience definitions from file
- ExportAudienceDefinitions - Exports a set of audience definitions to file
- ProcessSegments - Processes raw Eyeota segmentation files into campaign data files
- SetAudienceState - Set the active state on an audience
Functional Areas
- Automated Data Load and Refresh - Daily processing of 2 load projects: dsource1-audience (10-15 days of data) and dsource1-incremental (today's data)
- Audience Solution
- Audience creation - a web-app for audience creation (accessed externally by the Audience creation team) using the dsource1_audience project
- Automated Audience Export and Distribution - an automated process that extracts and distributes daily audience files from the dsource1_incremental project. Note: this is just the data received in the last cycle.
- DataHub Solution
- Automated datasource package creation and deployment - a DataJet package of the data contained in dsource1_audience
- Datasource segment integration in Marketplace Extracts - Injection and linking of the dsource1_audience data for use in the DataHub
Automated Data Load and Refresh
Both the Audiences and DataHub solutions depend on the Automated Load and Refresh Process, which consists of two parts:
- DSource1_Daily_Audience_Extract.json - this script processes today's files and creates the audience extract files.
- Dsource1_Load_And_Package.json - this script creates the full DataSource that is used by Audience Builder and DataHub
Process Overview
Each project uses the same methodology to process the raw data using the ProcessSegments method. This method takes raw data files from the data supplier and processes them to create the DATA_XXX_* tables.
The workflow is as follows:
- Receipt of Raw Data
- Transfer and decompression of raw data into sub folders of the Source Folder - called Daily Source Folders
- Datajet Segment Processing of specified Daily Source Folders , generating
- Segment data files - binary campaign data files used to calculate which ids are present in which segments and audiences
- Hash-Key files - list of unique ids plus unique email hashes.
- Creation of Primary Contact Table by Loading Master Hash-Key file - e.g., DATA_XXX_FULL, DATA_XXX_EXTRACT
Receipt of Raw Data
Data comes from the vendor as compressed *.tsv files which are stored in Daily Source Folders.
Each file has the format:
HEMSHA2_Key Key_Type {Array of Segment IDs}
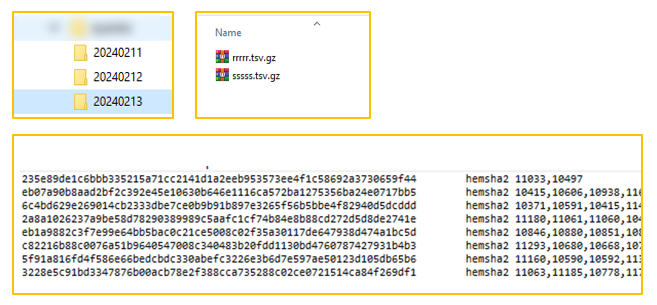
Each Raw Data file contains a list of HEMSHA2 Hash of an email address - called a Hash-Key - as well as an array of segments that apply for that Hash-key.
0009416759a1f763ceac6e24c152335aa61ad1128da9a3610a0703ccde4e24bd hemsha2 11470,11225,13529,16540,19176,21584- *.gz
- *.zip
- *.rar
Transfer and de-compression of raw data
Raw Data files are organised into Daily Source Folders. These Daily Source Folders are stored under the Source Input Folder (e.g. ...DSource1\...\US) and take the format YYYYMMDD.
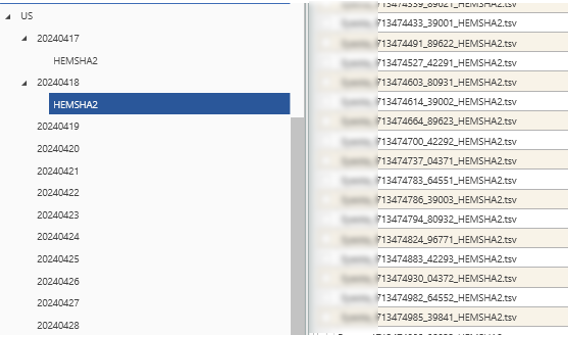
The HEMSHA2 raw data files are stored in a sub directory:
...\YYYYMMDD\HEMSHA2
Either this needs to be specified as a childfolder in the ProcessSegments call, or the data needs to be unzipped into the daily source folder:
{
"method": "ProcessSegments",
...
"childfolder": "HEMSHA2",
...
}Segment Processing
Data is processed using the ProcessSegments method. This method:
- Associates each unique hash key in the Daily Source Folders with a system generated integer key
- For each Daily Source Folder, creates a binary data file (called segX.dat) file for each segment. Each data file contains a list of all the unique keys that are in the segment. These binary segment files are stored in Daily Segment Folders within the Segment Root Folder. (Note: The segment root folder is defined in the project's campaign definition file)
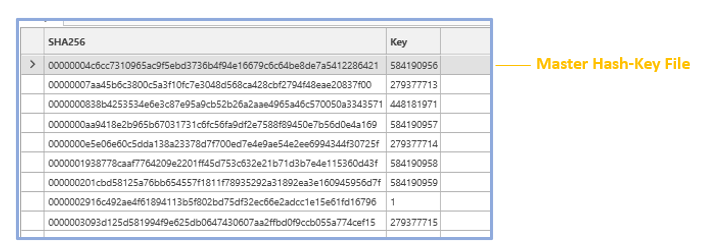
- Creates a Master Hash-Key file that contains the mapping between the HEMSHA2 key and the system generated integer key
- Hash-Keys are the Hash Key's supplied by DataSource Supplier in the raw data files
- Integer-Keys are the keys generated each day by the ProcessSegments method. These are used in order to minimise disk space requirements for the processed segment data and system response times and do not persist between data updates.
{
"method": "ProcessSegments",
"sourcepath": "/home/.../datasources/.../dsource1/.../US/",
"targetpath": "/home/.../datasources/campaignRoot/realm-name/dsource1-audience",
"segspath": "/home/engine/datasources/campaignRoot/realm-name/dsource1-audience/segs",
"childfolder": "HEMSHA2",
"reportFile": "%OUTPUT%SegmentProcessReport.json",
"latestFolders": 15,
"-note": "latestFolders 1 just loads most recent daily source folder",
"maxLines": 1500000000,
"numericFoldersOnly": true,
"ignoreCompressedFolders": true,
"finalConvert": true,
"cleanOnStart": true,
"sample": false,
"writekeys": true,
"description": "Process DSource1 Segments",
"project": "dsource1-audience"
}Creation of Primary Contact Table
The Primary Contact Table is a DataJet table containing at minimum Hash-Keys and their matching Integer-Keys. It is created by loading the Master Hash-Key File generated by ProcessSegments.
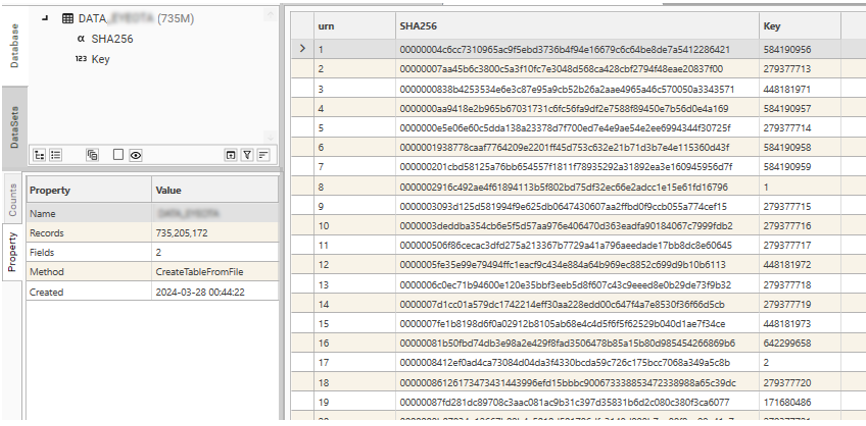
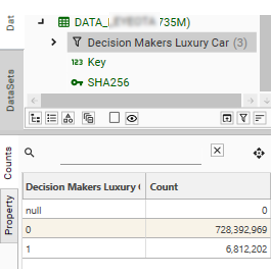
The following shows the CreateTableFromFile method used to load the DATA_XXX Primary Contact table:
{
"method": "CreateTableFromFile",
"action": "LOAD",
"table": "DATA_XXX",
"filename": "%DATAPATH%.../US/maindatafile.txt",
"definition": [
"SHA256|CONTINUOUS|STRING|",
"Key|CONTINUOUS|INTEGER|"
],
"loading": [
"SHA256",
"Key"
],
"preHeaderSkip": 0,
"dateFormat": "YYYY-MM-DD",
"fileFormat": "ASCII8",
"skipFirstLine": false,
"delimiter": "TAB",
"stripCharacter": "",
"dateTimeFormat": "YYYY-MM-DD HH:MM:SS",
"project": "DSource1_Test",
"sample": false,
"ignoreErrors": false
}Audience Extract Solution
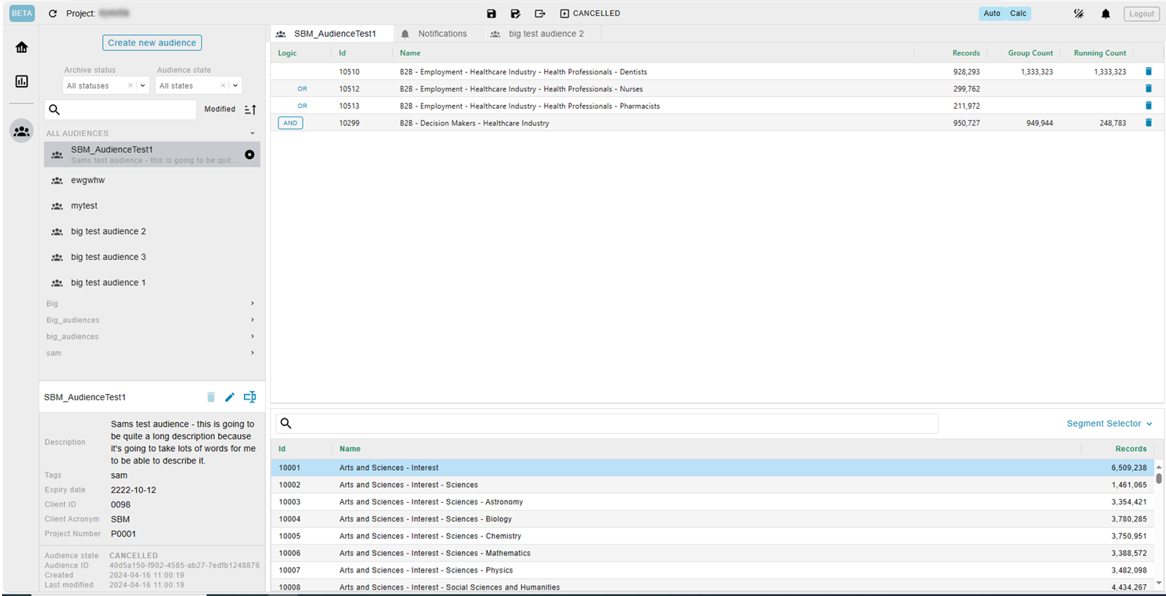
To access the Audiences App, go to:
webhome.allantgroup.com/amp/{realm-name}
Select the Audience Extraction Project project (VENDOR_Audience), and the audiences app will open:
Audience Creation
For the Audience Extraction Solution, audiences will be created in the web app.
Storage of Audiences
Audience details are stored in Mongo on the active Realm.
Automated Audience Export and Distribution
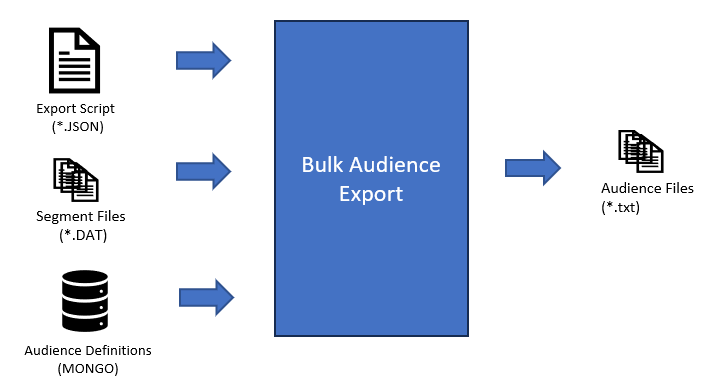
Export Methods
Live audiences are exported daily - note that audiences are exported from the dsource1-incremental project. Audiences can be exported using one of two methods:
- ExportAudience - exports the hash-keys for the specified audience id to an individual *.txt file.
- BulkExportAudiences - exports all audiences of specified status into appended files of a specified size (default = 1 million hash-keys)
ExportAudience contains Hash keys only, whereas BulkExportAudiences contains a configurable set of fields, e.g., Hash|CountryCode|AudienceID
{
"method": "BulkExportAudiences",
"status": "*",
"fileStub": "testexport",
"prefix": "US\t",
"suffix": "\t%AUDIENCEID%",
"recordsPerFile": 50000,
"project": "dsource1-incremental",
"description": "Export all audiences of all status"
}Location of Export Files
The location of the export files is determined by the project's Campaign Definition File. (See Campaign Prototype: How to make a system campaign enabled) for more details on system and project configuration.
{
"key": "DATA_XXX.key",
"export": {
"fields": [ "DATA_XXX.hash" ],
"root": "D:/Datajet/campaignExports/"
}
}Sample Scripts
eyeota-incremental
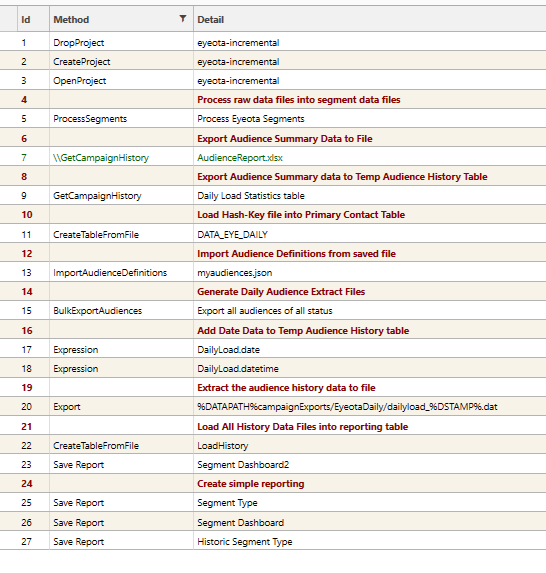
See sample script: eyeota-incremental for further details
eyeota-audience
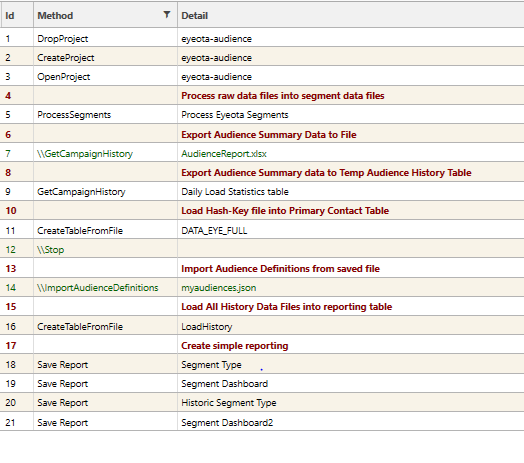
See sample script: eyeota-audience for further details
DataSource Marketplace Solution
The DataSource Marketplace Solution makes the vendor segmentation data available for use in client projects, or the DataHub.
There are 2 ways that the this type of vendor data can be integrated into other projects:
- simple injection
- campaign injection
Simple Injection
Simple Injection is where a package is created from the primary contact table (DATA_DSOURCE_FULL) and then this package is injected into other projects. This injected table can then be linked via hashed email to an identification table - for example DATA_AWI or a derivative.
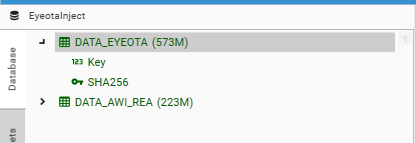
Appending Segmentation Data
For the injected DATA_DSOURCE table to be useful in this scenario, it usually needs to have had segmentation information appended to it as DataSet Fields or Datasets.
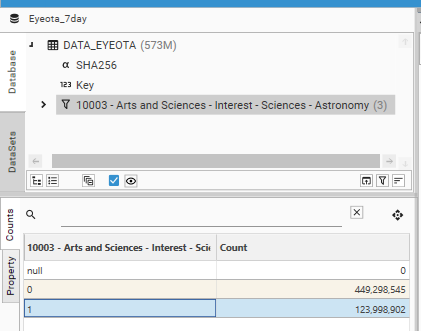
It is not recommended to add too many dataset fields to the Primary Contact Table, but in many scenarios this will provide sufficient value to the consumer project.
To add DataSet Fields to the DATA_DSOURCE table, do the following:
- Make the project campaign enabled by adding a campaign definition file for the project to the realm folder in campaignRoot (see How to make a system campaign enabled for further details)
- Close and re-open the project
- Open the Campaign Selector report (Campaign | Selection | Remote)
- Create an audience by clicking on the New Audience icon and giving the audience a name
- Double-click a row in the Segment list to add the row to the audience

- Calculate the audience by clicking Run
- Add the audience as a field to the Primary Contact Table (DATA_DSOURCE) by selecting the Create Dataset icon
Campaign Injection
Campaign Injection is where the DATA_DSOURCE table is injected into a project that has also been campaign enabled.
A project is campaign enabled if:
- It has a campaign definition file in the campaignRoot folder.
- It has access to the datasource segmentation data
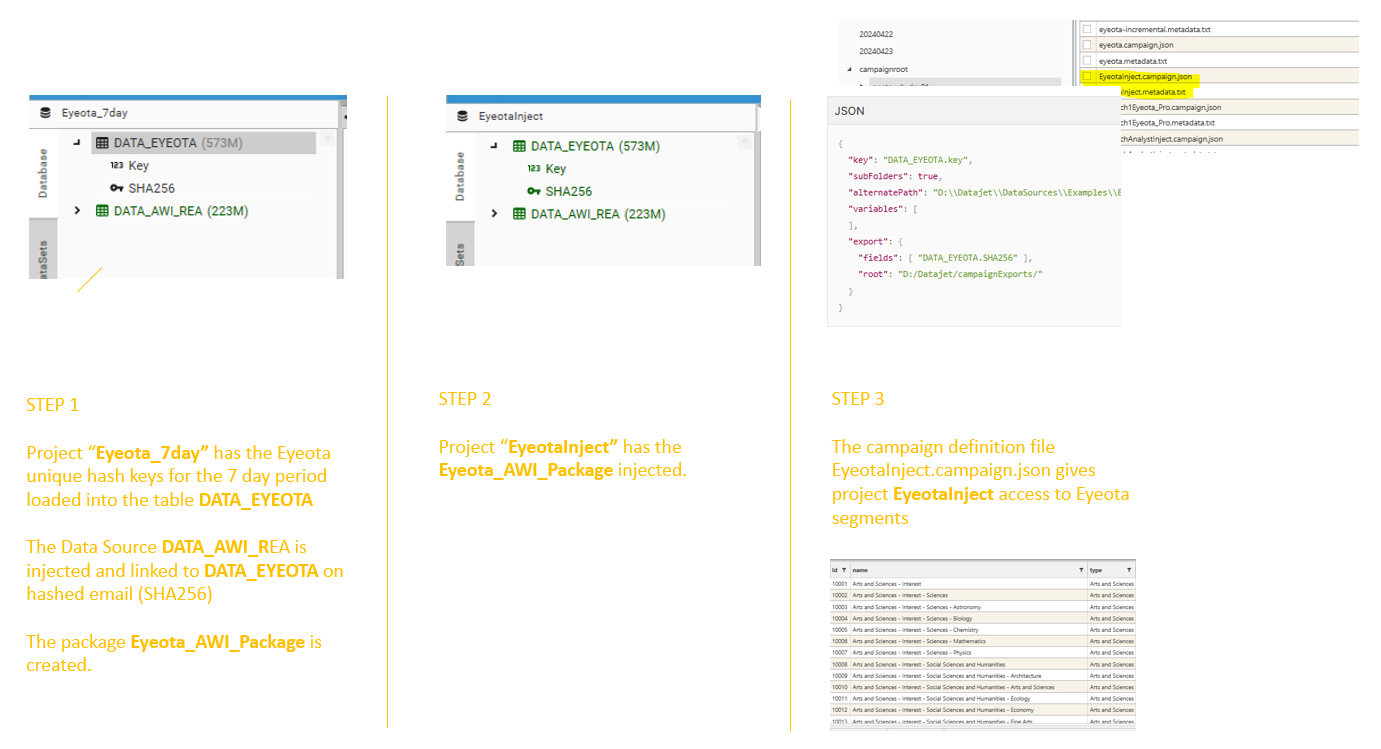
Campaign Injection allows a user to access all Datasource segments and create datasets from them.
{TODO: What can usefully be done with these datasets?}
Combining DataSource segments to build custom audiences/datasets
Combing DataSource segments with data from other fields
Using DataSource segments in analysis reports
{TODO: What needs to be done with these datasets?}
Automated DataSource package creation and deployment
{TODO: How to create a package}
{TODO: How to deploy and inject}
DataSource segment integration in Marketplace Extracts
{DataJet Desktop UI}
{TODO: Show selecting from campaign}
{TODO: Show Combined Segment}