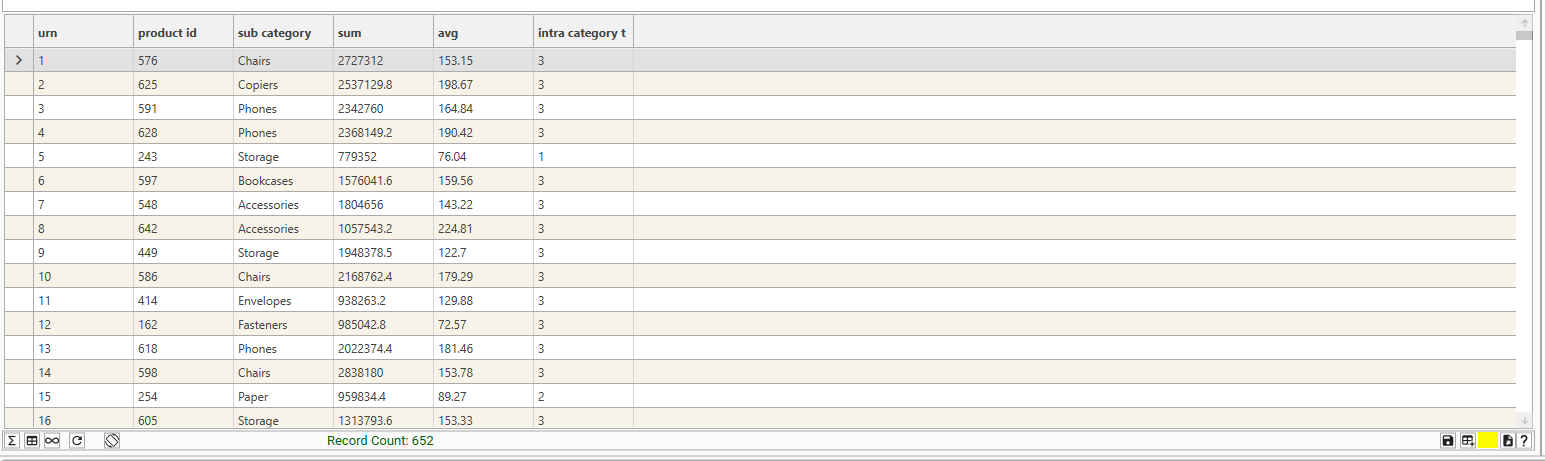
Key Features
The key features of this release are:
- Performance Enhancements to audience calculation times
- Implementation of audience caching
- Restricted export to workbook from DataView for limited access accounts
- Improved error messaging in ProcessSegments
- BulkExportAudiences fails if directory doesn't exist
- Server-side storage of audience definitions
Changes to API Methods
| Method | Description of change |
|---|---|
| ProcessSegments | Changes to processing to store only unique IDs in segment files |
| CountCampaignDataset | Implementation of caching structure |
| BulkExportAudiences | Error generated if export location doesn't exist |
Feature Details
Performance Enhancements to audience calculation times
A modified method of processing is now available for ProcessSegments via the "collated":true flag.
This method forms additional processing during the load and processing of the raw data so that audiences are calculated more quickly in the audiences app. A consequence of this modification is the change in the segment folder structure. Rather than segment files being stored in daily folders, all segment files are now stored in the same folder.
All duplicates are now removed from the segment folders, so the segment records value refers to the number of unique keys in the segment.
Details of which folders have been processed are available in the ProcessSegment report.
See Audience Selection Overview for an overview of the approach used to create audiences.
Implementation of audience caching
Audiences now implement caching. This reduces recalculation time when a modification is made to an existing audience.
The audience cache can receive up to 256 entries. Once exceeded the oldest entry is removed first. Each call to CountCampaignDataset creates a cache entry if the audience hasn't been seen before.
In a situation where there are a top N audiences that get used each time the data is refreshed, CountCampaignDataset for the audience could be called at the end of the load process to pre-cache the counts.
Restricted export to workbook from DataView for limited access accounts
Limited access accounts will no longer be able to export data from the DataView report - the option has been removed.
Improved error messaging and reporting in ProcessSegments
ProcessSegments will now generate an error if the location specified in "reportFile" doesn't exist and will not run until this is corrected.
"reportFile": "%campaignRoot%/%realm%/%CURRENT_PROJECT%/reports/SegmentProcessReport%DSTAMP%.json",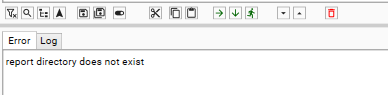
The report file structure has also been altered to include the following additional information:
- files_processed - total number of files processed
- folders_processed - the names of all folders processed
- folders_processed_lines - the number of lines processed per folder
- processedDirs - the names of all output directories
{
"ProcessSegment": "2024.7.22.1",
"sourcepath": "...mft/US/",
"targetpath": ".../datasource-audience/",
"segspath": ".../datasource-audience/segs/",
"childfolder": "HEMSHA2",
"dirs": [
"20240707",
"20240706",
"20240705",
"20240704",
"20240703",
"20240702",
"20240701"
],
"writekeys": true,
"checking": false,
"sample": false,
"verbose": false,
"count": false,
"followonly": false,
"collated": true,
"files_processed": 757,
"folders_processed": [
"20240707/HEMSHA2",
"20240706/HEMSHA2",
"20240705/HEMSHA2",
"20240704/HEMSHA2",
"20240703/HEMSHA2",
"20240702/HEMSHA2",
"20240701/HEMSHA2"
],
"folders_processed_lines": [
535469843,
836427346,
109439092,
598006467,
738713871,
46902468,
93804936
],
"processedDirs": [
"20240707"
],
"totalLines": 2000000000,
"uniqueLines": 1179447368,
"maxLines": 2000000000
}BulkExportAudiences now fails if directory doesn't exist
Previously BulkExportAudiences would fail silently if the export location - as defined in the campaign definition file - did not exist. It will now raise an error.
"export": {
"fields": [ "entities.hash" ],
"root": "D:/Datajet/campaignExports/"
}Server-side storage of audience definitions
By default, audience definitions are stored in the mongo database on the realm and project in which they were created. To provide access to existing audiences within a project that is campaign enabled and/or has injected the campaign data, the audience definitions must be exported from the source project using ExportAudienceDefinitions and then imported into the target project using ImportAudienceDefinitions.
An alternative method for audience storage - similar to ScriptHub - is now available via the audienceStorageHub configuration setting in the djclient.cnfg file:
"audienceStorageHub": {
"method": "FILE",
"path": "/mnt/datajet/audienceHub"
}If this setting is present in the realm configuration file, campaign enabled projects for that realm will look to the Audience Hub for audience definitions rather than to the local mongo database.