Article in Progress
Use the Rank function to order sub-groups of data by a sort key.
The Ranking function is opened via Engineering | Ranking. The following inputs are required:
- Data to rank
- Data to group by
Rank requires the following data structure: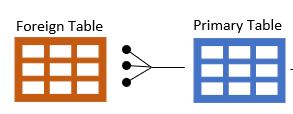
- A foreign table containing the data to rank,
- A primary table containing the key which will be used to group the data for ranking.
Basic Ranking Example
Goal: For each customer, rank their transactions from earliest to latest date (or vice versa).
Let's imagine we have a sales (or transactions) table that contains the following transaction details:
- Customer ID (identifies the customer who made the purchase)
- Date of Purchase (records exactly when the purchase was made)
- Transaction ID (uniquely identifies the purchase)
We want to give each transaction in the sales table a customer specific purchase number - so the customer's first purchase will be 1, their second second purchase will be 2, etc.
We can say that we want to rank [Sales.Customer ID] on or by [Sales.Date of Purchase]. This process will involve the following:
- Group by Customer
- Order By Date
- Assign ranks
In order to group by customer, we will need a table containing one record for every customer in the sales table - i.e., a table of unique customer IDs.
If a key table of unique customers doesn't already exist it can be created using the Make Key Table function or CreateKeyTable method. (This will extract the list of unique customers from the sales table and use them to create a new table, joined on customer ID.)
The resulting tables would look as follows:
- Primary Table (Key Table, or ONE side of a ONE to MANY join), e.g., Customer
- Foreign Table (MANY side of a ONE to MANY join), e.g., Sales
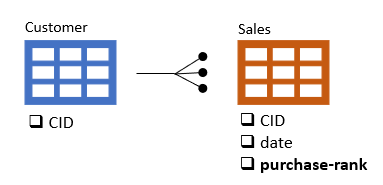
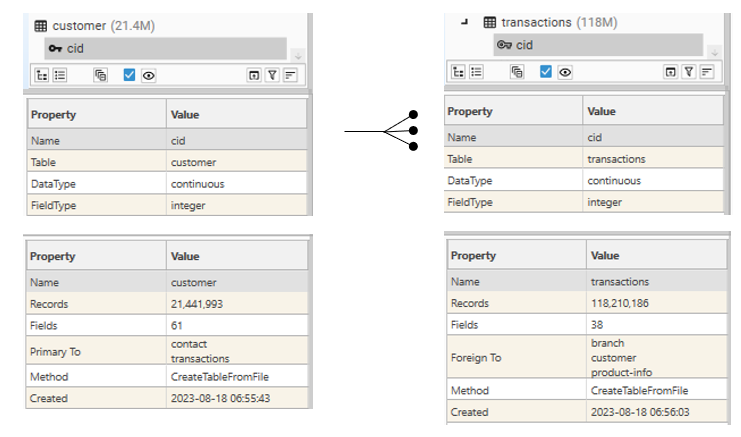 Customer -< Transaction tables joined on CID
Customer -< Transaction tables joined on CID
The Ranking function requires the following inputs:
- Primary table : e.g., customer table
- Foreign table: e.g., transactions table - must be joined to primary table
- Rank on: numeric field to rank on (e.g., sales.date)
- Name: This is the name of the generated output field (e.g., sales.purchase-rank)
The following optional inputs can be specified:
- Filter: An optional filter (or dataset). Only records in the Foreign table that are in the dataset will be included in the rank.
- Ascending: By default, the rank will be calculated in descending order (from largest key value to smallest key value). If ascending is true, the rank will be calculated in ascending order, from smallest to largest.
- Second Key: Sorts first by "Rank On" and then within each sub-group, but specified second key
- Always Increment: If true, if records in a sub-group have the same rank, will force the rank to be incremented for each record. (Note: The incrementation order is random)

Here we can see the output field (transactions.purchase-rank) for a specific customer (customer 1066).
- Purchase 1 was on 2019-07-13,
- Purchase 2 was on 2019-07-02
- etc:
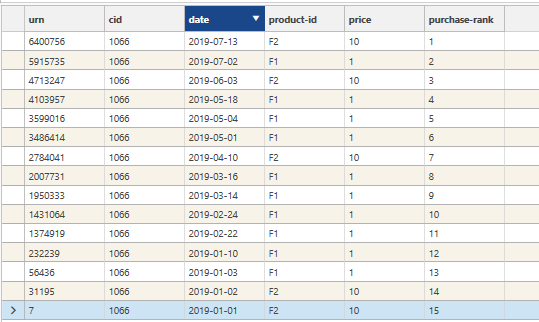 purchase-rank for customer CID=1066
purchase-rank for customer CID=1066
Limitations
Continuous Fields
[Rank On] must be a discrete field - the ranking algorithm will not directly rank a continuous field. However, it is a common requirement to rank continuous fields, and so the following options are available for transforming a continuous field into one that can be used by the ranking algorithm:
- Use the expression builder to manually remap the existing data into a smaller space (i.e., reduce the number of possible values)
- Use the built in remap function to automatically remap the existing data into a smaller space (v7.3.2.1 or later)
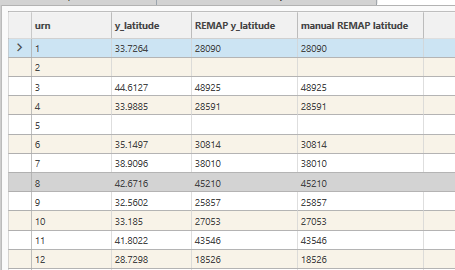
Expression Builder
Access the expression builder from Engineering | Expression Field. The following inputs are required:
- Name - the name of the new field
- Source field - the field to remap
- Source field minimum - the lowest value in the source field
- Source field maximum - the highest value in the source field
- Bin Count (also termed granularity, or cardinality) - the maximum number of unique values in the output field
- Target Datatype - integer
- Target Precision - 0
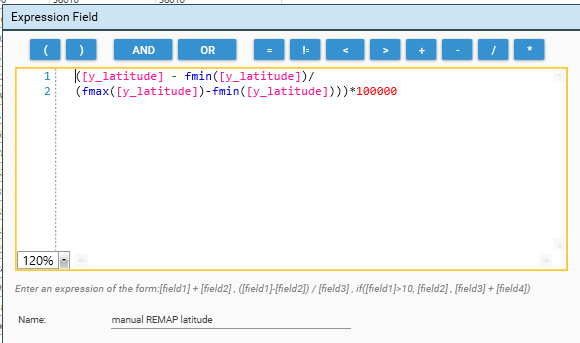
([y_latitude] - fmin([y_latitude]) / (fmax([y_latitude])-fmin([y_latitude])))*100000
- Source field - [y_latitude]
- Source field minimum - fmin([y_latitude])
- Source field maximum - fmax([y_latitude])
- Bin Count - 100000
- Target Datatype - integer
- Target Precision - 0
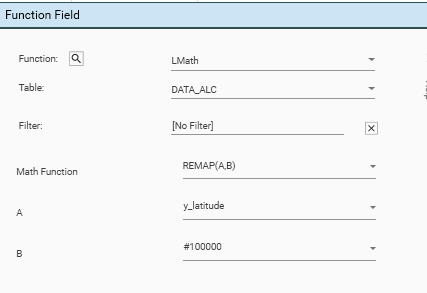
Remap Function
Access the remap function from Engineering | Function Field | Functions | LMath | Remap(A,B) or by right-clicking the field to remap and choosing Engineering | Functions | LMath | Remap(A,B) The following inputs are required:
- Function - LMath
- Table - the table containing the field to remap
- Math Function - REMAP(A,B)
- A - source field to remap
- B - Bin Count / Cardinality of output field
- Name - name of output field
Other Limitations
{TODO}
Questions about ranking limitations:
- What limits if any are there on the number of records in the foreign table?
- What happens if the machine doesn't have sufficient memory?
- How can you estimate the memory required for the calculation?
- What other tips are there to make ranking faster?
- If always increment is true, are there any rules about how the incrementation happens?
- how would you go about ranking string or alphanumeric fields? (What other technique could be used?)
- can doubles be loaded as discrete? And if so can they be used in ranking?
- What data-types does Rank accept?
Guidelines for working with Ranking
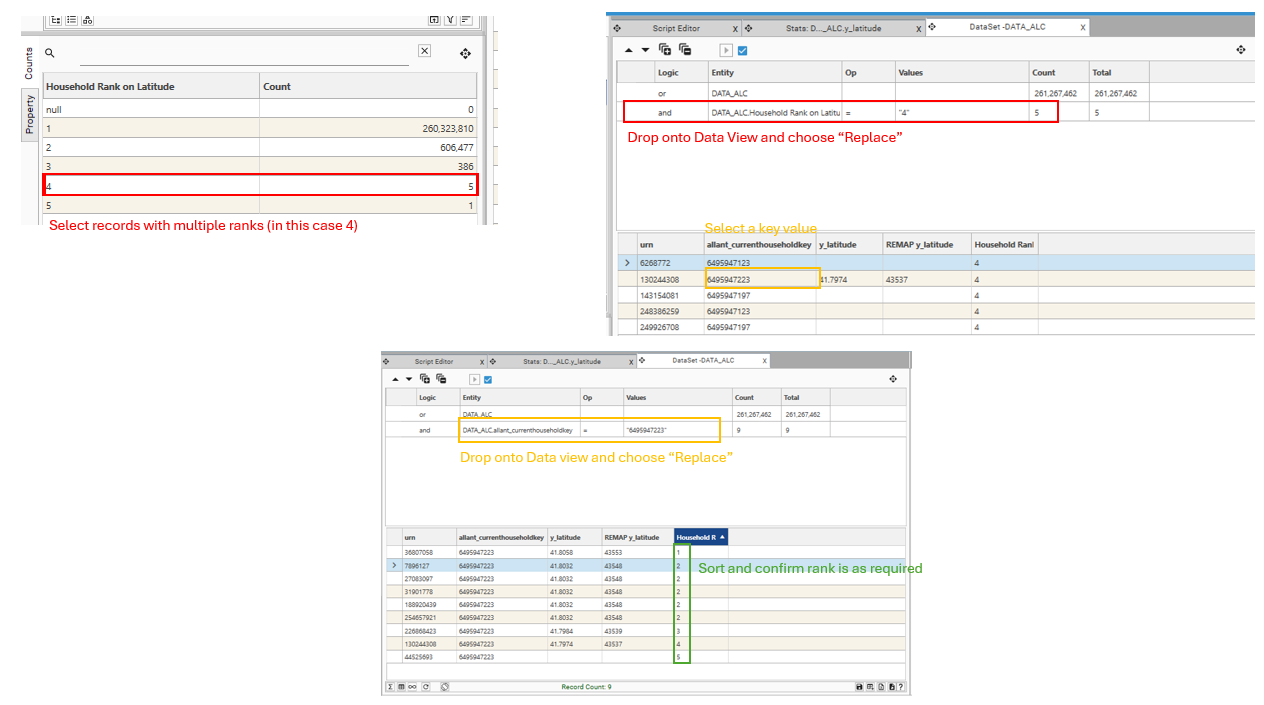
Use Dataset scratch to confirm rank orders are as expected, and tweak the ranking method accordingly:
- In Project explorer, select the Foreign Table, select the Key field (i.e., the field that links the primary and foreign table), right-click and choose Data View
- Select the "Rank On" field in the project explorer and drag to dataview to add to the grid. If a discrete remap field is being used because the original field is continuous, add this as well
- Add the Rank output field to the data view
- In the Project explorer, select the Foreign Table, then select the Rank Output field. In the context panel, select the "Counts" tab, and select a dataset of rank greater than or equal to 2 (ideally, select the largest or second largest value of rank - this will give enough records to confirm the ranking is working as expected).
- Drop this dataset onto the DataView and choose "And" or "Replace"
- Select a cell from the key field column, hold down CTRL and drag and drop the cell back onto the data grid. Choose "Replace". The grid will now be displaying only records for that particular key.
- Click on the Rank Output column to sort the grid by rank
- Confirm that the rank order matches the order of the field that is being sorted.
- The most common changes that are required are:
- Re-calculate with "Ascending" set to true
- Re-calculate with "Always Increment" set to true
- Re-calculate after applying a filter
- Do some other kind of data transformation on the Rank On field, and then re-calculate.