Engineering Functions
Engineering functions can be used to create and transform fields. They can be accessed directly through the DataJet Desktop User Interface and also through ETL scripts
See Also:
https://datajetsoftware.atlassian.net/wiki/pages/resumedraft.action?draftId=471564295
TODO: Property Window
TODO: Script Editor
TODO: Engineering Window
- CombinedDimension
- CombinedDimension_NS
- CombinedIndex
- CompositeLongKey
- CopyDiscrete
- CopyDiscreteIndex
- FLOORMIN(A,B)
- HOD(A)
- HOUR(A)
- HOURSBEFOREMAX(A)
- HOURSDIFF(A,B)
- MINSDIFF(A,B)
- MINUTE(A)
- SECOND(A)
- SECSDIFF(A,B)
Function Group | Functions | Description | Components | Example Script |
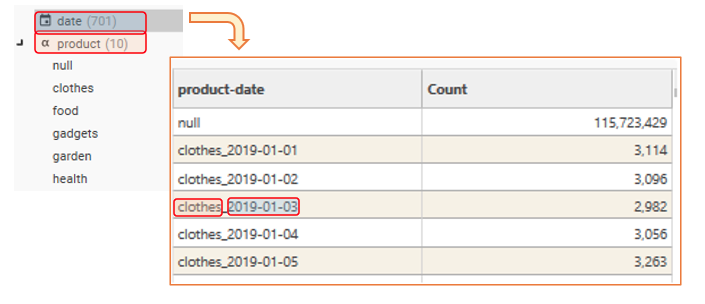
CombinedDimension | CombinedDimension | Create a new discrete field from the concatenated string values for fields 1 to 6 separated with underscores.e.g. Field1Value &”_” & Field2Value clothes_2019-01-01 Example output:
| Table: “targetTable”The target table on which the new field will be created Filter : “dataset{}”Optional. Must come from target table. Records not in the filter will have a null value in the resulting field. Fields1-6: “p1”… “p6”All fields must come from target table. Only discrete fields are supported. If a continuous key field needs to be used in a combined dimension, first transform the key field using the CONCAT function. Include Null: “includeNull”If selected/true, then any null values in Fields1-6 will be included and denoted using null. e.g. clothes_null or null_2019-0101 |
|
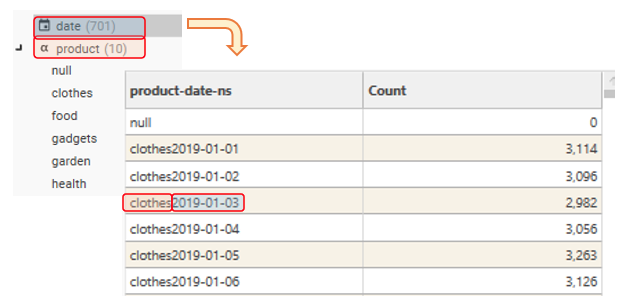
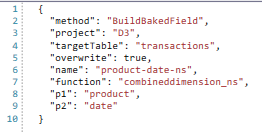
CombinedDimension_NS | CombinedDimension_NS | Create a new discrete field from the concatenated string values for field 1 to 6. No separator is used to delimit the component values.e.g. Field1Value & Field2Value clothes2019-01-01 Example output:
| Table: “targetTable”The target table on which the new field will be created Filter : “dataset{}”Optional. Must come from target table. Records not in the filter will have a null value in the resulting field. Fields1-6: “p1”… “p6”All fields must come from target table. Only discrete fields are supported. If a continuous key field needs to be used in a combined dimension, first transform the key field using the CONCAT function. Include Null: “includeNull”If selected/true, then any null values in Fields1-6 will be included and denoted using null. e.g. clothes_null or null_2019-0101 |
JSON for CombinedDimension_NS supports the same parameters as CombinedDimension |
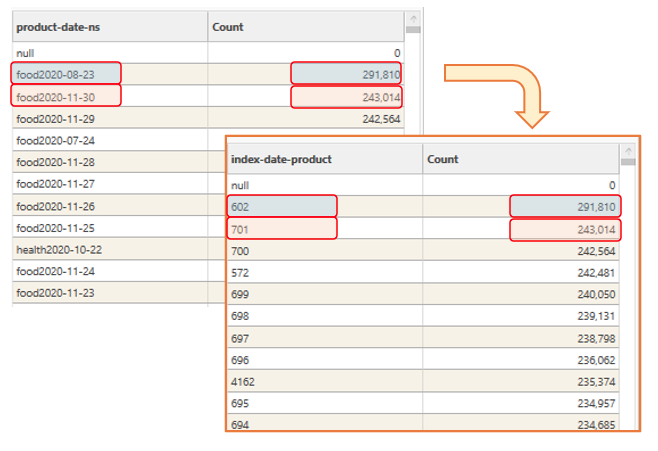
CombinedIndex | CombinedIndex | Create a new discrete integer field by multiplexing the unique values for fields 1 up to 6.Each value|value combination for the selected fields is given a unique integer value. This creates a compact index without losing granularity. e.g. Field1_Value1 = 1, Field2_Value1 = 600 Index_Field1Value1_Field2Value1 = 601 Example Output:
| Table: “targetTable”The target table on which the new field will be created Filter : “dataset{}”Optional. Must come from target table. Records not in the filter will have a null value in the resulting field. Fields1-6: “p1”… “p6”All fields must come from target table. Only discrete fields are supported. If a continuous key field needs to be used in a CombinedIndex, first transform the key field using the CONCAT function. Include Null: “includeNull”If selected/true, then any null values in Fields1-6 will be included in the index. |
|
CompositeLongKey | CompositeLongKey | Combined the specified low (L) and high(H) continuous integer fields into a continuous long integer field.The intermediate field is defined as (L*M)+H TODO: Show how calculation works | Table: “targetTable”The target table on which the new field will be created Filter : “dataset{}”Optional. Must come from target table. Records not in the filter will have a null value in the resulting field. High Key: “p1”TODO: limits etc - what is an integer? Low Key: “p2”Multiplier : “p3” |
|
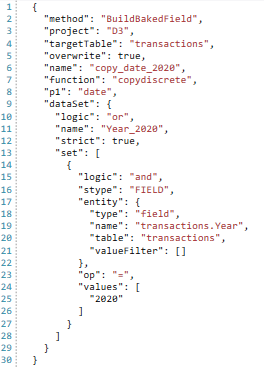
CopyDiscrete | CopyDiscrete | Makes a copy of the discrete source field.The function will not work if used with a continuous data type. Continuous data types can sometimes be transformed using the CONCAT function. For more information on field types, see Field Datatypes Use this function with a filter to remove unwanted values from a discrete field – or to reduce the number of discrete values for various multi-dimensional analytics. | Table: “targetTable”The target table on which the new field will be created Filter : “dataset{}”Optional. Records not in the filter will have a null value in the resulting field. TODO: Does filter need to come from Target table? Source Field: “p1”Any discrete field on the target Table. |
|
CopyDiscreteIndex | CopyDiscreteIndex | Makes a copy of the source discrete index, filtered by the optional dataset.TODO: What is difference between CopyDiscrete and CopyDiscreteIndex? | Table: “targetTable”The target table on which the new field will be created Filter : “dataset{}”Optional. Records not in the filter will have a null value in the resulting field. Source Field: “p1”Any discrete field on the target Table. | |
DateTimeTransform | FLOORMIN(A,B) | Rounds a DateTime field down to a given interval. e.g., rounds down to the nearest hour, 15 mins etc | Table: “targetTable”The target table on which the new field will be created Filter : “dataset{}”Optional. Records not in the filter will have a null value in the resulting field. A : “p1” The DateTime field to be transformed. Must be on the target Table. B : “p2” The interval to round down to. | |
HOD(A) | Hour Of Day | |||
HOUR(A) | Hour of DateTime A | |||
HOURSBEFOREMAX(A) | Returns number of hours before the maximum value of A | |||
HOURSDIFF(A,B) | Returns count of difference in Hours between Hours of A and Hours of B | |||
MINSDIFF(A,B) |
| |||
MINUTE(A) |
| |||
SECOND(A) |
| |||
SECSDIFF(A,B) |
| |||
SOD(A) |
| |||
TRUNKSEC(A) |
| |||
YMDH(A) |
| |||
DateTransform Note: | ABSDAYSDIFF(A,B) | Absolute Days difference between 2 dates, where A is the lower date. | ||
AGE(A) | Age in years at the time the field is built. | |||
AGE(A,B) | Age in years in relation to the field or immediate value in B | |||
ANNIVERSARYDAYS(A,B) | Number of days until or after, if negative, the anniversary defined by the month and day of B, in year of B. | |||
DADD(A,B) | The date in B days from A | |||
DATE(A) | Create a date field from a DateTime value | |||
DATEFROM(A,B,C) | Create a date field from a Year (A), Month(B), and Day(C) | |||
DAY(A) | From 1 to 31 | |||
DAYSAFTERMIN(A) | Number of days each value in a date field is before the minimum value of that field. | |||
DAYSBEFOREMAX(A) | Number of days each value in a date field is before the maximum value of that field. | |||
DAYSDIFF(A,B) | Days difference between 2 dates, where A is the lower date. | |||
DAYSDIFF_MXONB(A,B) |
| |||
DOY(A) | From 1 to 366 | |||
MAX(A,B) | The latest of the two given dates | |||
MIN(A,B) | The earliest of the two given dates | |||
MONTH(A) | Month as a value from 1 to 12 | |||
SMONTH(A) | Name of Month, as “01-January” to “12-December” | |||
SWEEKDAY(A) | From “1-Monday” to “7-Sunday” | |||
WEEKDAY(A) | From 1 to 7 | |||
WEEKOF(A,B) |
| |||
WOY(A) | From 1 to 53 | |||
YEAR(A) | Extract the year from a date | |||
YEARMONTH(A) | An integer concatenation of year and 0-leading month. E.g., 199201, 199212 | |||
YEARQTR(A) | An integer concatenation of year and 1-leading quarter. E.g., 20191, 20203 | |||
YEARWOY(A) | An integer concatenation of year and 0-leading week of year. E.g., 199201, 199252 | |||
DescendingIndex |
|
| ||
DistinctByKey |
| Create a flag field, set to true for the first occurrence of each unique value of a key field, for the set of records linked to each key in a primary table. | Key Table Distinct Key | |
DMath Floating Point Math Functions The first parameter specifies the function to use, subsequent parameters are the fields to use for values A-F. Alternatively, a field can be replaced with an immediate value by preceding the value with a # character Note: Supports a universal dataset, any records not in this dataset will resolve to null. If any of the source fields contain a null the result will be null, unless “Treat Null As Zero” is selected, in which case all field values of null will be assumed to be zero. Dividing by zero will produce a null. | A | |||
A/B |
| |||
A+B |
| |||
A-B |
| |||
A*B |
| |||
A*B*C |
| |||
(A*B)/C |
| |||
(A+B)/C |
| |||
(A-B)/C |
| |||
(A-B)/B |
| |||
A+B+C |
| |||
A+B+C+D |
| |||
(A*B)+(C*D) |
| |||
(A*B)+(C*D)+(E*F) |
| |||
INT(A*B)/B | Int() is executed before the division | |||
INT(A/B)*B | Int() is executed before the division | |||
MAX(MIN(A,B),C) |
| |||
MAX(A,B) |
| |||
MIN(A,B) |
| |||
RAND(A) | Uniform random distribution between 0 and n-1 | |||
NRAND(A) | Product of field or immediate value and a sample from the normal distribution with a mean of 1 and standard deviation of 1 | |||
BRAND(A) | Selection from a Bernoulli distribution, with field parameter or immediate value as probability of the new field being 1. | |||
ANRAND(A) | Product of field or immediate value and a sample from the absolute value of normal distribution with a mean of 1 and standard deviation of 1 | |||
MIN(A+B*ANRAND(C),D) |
| |||
LOG(A) | Base 10 logarithm | |||
LN(A) | Natural logarithm | |||
LOG(A/B) | Base 10 logarithm | |||
LN(A/B) | Natural logarithm | |||
MOD(A,B) |
| |||
FirstDiscrete |
| Creates a flag field where the first occurrence of each unique value in the specified field is set to 1. | Distinct Key | |
FirstDiscreteByIndex |
| Creates a flag field where the first occurrence of each unique value in the specified field is set to 1 – but derived as if the table by in order of the sort field. | Distinct Key Sort Field | |
FirstDiscreteByInvertedIndex |
| Creates a flag field where the first occurrence of each unique value in the specified field is set to 1 – but derived as if the table by in descending order of the sort field. | Distinct Key Sort Field | |
FLogic | A=B |
| ||
A!=B |
| |||
A |
| |||
A<=B |
| |||
A>B |
| |||
A>=B |
| |||
IntegerSequenceKey |
| Produces a field that is the record number in a table, stored as an integer. | ||
LMath Integer Math Functions The first parameter specifies the function to use, subsequent parameters are the fields to use for values A-F. Alternatively, a field can be replaced with an immediate value by preceding the value with a # character Note: Supports a universal dataset, any records not in this dataset will resolve to null. If any of the source fields contain a null the result will be null, unless “Treat Null As Zero” is selected, in which case all field values of null will be assumed to be zero. Dividing by zero will produce a null. | A |
| ||
A/B |
| |||
A+B |
| |||
A-B |
| |||
A*B |
| |||
A*B*C |
| |||
(A*B)/C |
| |||
(A+B)/C |
| |||
(A-B)/C |
| |||
(A-B)/B |
| |||
A+B+C |
| |||
A+B+C+D |
| |||
(A*B)+(C*D) |
| |||
(A*B)+(C*D)+(E*F) |
| |||
MAX(MIN(A,B),C) |
| |||
MAX(A,B) |
| |||
MIN(A,B) |
| |||
RAND(A) | Uniform random distribution between 0 and n-1 | |||
NRAND(A) | Product of field or immediate value and a sample from the normal distribution with a mean of 1 and standard deviation of 1 | |||
BRAND(A) | Selection from a Bernoulli distribution, with field parameter or immediate value as probability of the new field being 1. | |||
ANRAND(A) | Product of field or immediate value and a sample from the absolute value of normal distribution with a mean of 1 and standard deviation of 1 | |||
MOD(A,B) |
| |||
GCD(A,B) | The greatest common denominator of A and B | |||
LCM(A,B) | The least common multiple of A and B | |||
IF(A>B)C:D |
| |||
IF(A>=B)C:D |
| |||
IF(A |
| |||
IF(A<=B)C:D |
| |||
IF(A=B)C:D |
| |||
IF(A!=B)C:D |
| |||
A-MIN(A)+1 |
| |||
LongSequenceKey |
| Produces a field that is the record number in a table, stored as a continuous long integer. | ||
MakeContinuousKey |
| Produces a new continuous integer field from a discrete field on any data type | Discrete Field | |
Quantile |
| Creates a quantile from a discrete numeric field with specified number of elements. The function supports a field of 5 to 250 elements. | Quantile Field Elements | |
SessionIdentifier |
| On a foreign (many-side) table, for the set of records corresponding to each key in the primary (one-side) table, create a sequence counter (an integer discrete field) for each set of records where the elapsed timestamp since the last entry seen is less than the specified duration, in seconds.
The foreign table must be in timestamp order. | Primary Table Timestamp Duration Secs | |
String | CONCAT(A,B,C,D,E,F) | Creates a string field by concatenating given field values | ||
DATEFROMSTRING(A,B) |
| |||
EXTRACTIJKEY(A,B) |
| |||
EXTRACTJKEY(A,B,C) |
| |||
FIRSTPOPULATED(A,B,C,D,E,F) |
| |||
LEFT(A,B) |
| |||
LEFTOF(A,B) |
| |||
LPAD(A,B,C) |
| |||
RIGHT(A,B) |
| |||
RIGHTOF(A,B) |
| |||
STRLENGTH(A) |
| |||
WILDICAST(A) |
| |||
UserAgent | BROWSER(A) |
| ||
DEVICENAME(A) |
| |||
OS(A) |
|